VPN Detection
Detecting VPN's is slightly harder than detecting proxies. VPNs are implemented in the network level of the OSI model compared to proxies, which are implemented in the transport layer. This means that all IP packets from a certain network interface are routed via the VPN server, which then in turn relays the packets to the destination. There are not as many side-channel attacks (for example from the browser via JavaScript) to perform with VPN detection as it is the case with proxy detection.
Nevertheless, clients that use VPN's exhibit very distinct characteristics which allow to interpolate VPN usage with high confidence.
Setting Up a WireGuard VPN Server
In this section, it is demonstrated how a WireGuard VPN server can be installed in a few easy steps. The purpose of this section is to show how easy it is to create dedicated VPN infrastructure from scratch. The open source VPN project WireGuard will be used. WireGuard's self description states:
WireGuard® is an extremely simple yet fast and modern VPN that utilizes state-of-the-art cryptography. It aims to be faster, simpler, leaner, and more useful than IPsec, while avoiding the massive headache. It intends to be considerably more performant than OpenVPN. WireGuard is designed as a general purpose VPN for running on embedded interfaces and super computers alike, fit for many different circumstances.
It is advised to install the VPN on a cloud computing instance, preferably on a Linux server. The following GitHub repository will be used to setup WireGuard very quickly: WireGuard Installer
curl -O https://raw.githubusercontent.com/angristan/wireguard-install/master/wireguard-install.sh
chmod +x wireguard-install.sh
./wireguard-install.shThe install script asks for various questions during the installation process. It is advised to go with the default settings. In the end of the installation process, you will receive a client WireGuard configuration file. Download this file to your local computer.
You can use WireGuard either from your phone or your computer. You will have to install a WireGuard client application. For example, you can install the WireGuard Android App for your Android Phone.
Now open the WireGuard client application and import your configuration file that you obtained when you installed the server. You are now connected to your own VPN server!
You can now test if this website can detect you by visiting proxydetect.live
VPN Detection Methods
There exist many different techniques that allow to detect VPN connections. However, one detection method alone is not sufficient, because detection tests suffer from false positive. The combination of many independent tests gives a VPN score with high confidence.
Timezone and Language
Browser API's have all kinds of language and localization settings that can be accessed with JavaScript. For example, the timezone or languages settings can be read from JavaScript. Those settings correlate with the geographical position of the user controlling the browser.
For example, the website locatejs.com displays all relevant attributes that allow to interpolate the geographical location. The project is open sourced and can be accessed at github.com/z0ccc/LocateJS.
At the same time, the IP address of your connection can be geolocated by using IP geolocation databases. If there is a difference in the two geographic locations, it can be assumed that the reason could have been VPN usage. This blog article explains how an IP address geolocation database can be build from scratch.
Response Time
VPN servers are essentially an artificial additional Internet hop over which a client relays its IP packets. This artificial relay can be detected based on the fact that unusually high round trip times are not common in the Internet, since the Internet has a shortest-path routing paradigm by default.
Put differently: What is the maximum latency IP packets can take in the Internet? When a client is located in London (UK) and is visiting an Australian Server, the average latency will be in the range of 300ms - 400ms. There is no larger distance on the globe than that, therefore, larger latencies cannot be of "organic" nature.
There exist of course many reasons why a non-VPN connection may take longer than the maximum latency theoretically allows. However, there are some peculiarities with VPN connections with suspiciously large latencies:
- Latency measurements from VPN servers are often stable. If N=10 latency measurements are taken, the variance of all latency measurements is small and the distribution is very stable. This is often not the case with connections that have high latencies for organic reasons such as congestions, network issues or long distance wireless networks. With VPN connections however, the VPN server is often hosted in high bandwith and reliable datacenters.
- The exit IP address belongs to a datacenter or hosting provider. VPN services often make use of lesser known hosting providers.
Distance to Latency Ratio
In a first step, a large ground truth table of latency measurements from connections that are not using a proxy or VPN is compiled. The collected latency measurements are placed in relation to the geographical location of the client and the assumed initial TTL (from the IP header) of the client.
The geographical location can be obtained by using a IP to location database and the initial TTL of the client can be assumed, since most modern operating systems either use a default TTL of 64, 128 or 255. If necessary, the initial TTL can be obtained by minimizing the hop-distance of the server to the client.
After the ground truth table of latencies and TTLs is built, it is possible to answer the question: "How long in terms of latency and TTLs does an ordinary client from a certain region need to reach the detection server?"
If a network flow from a test session significantly deviates from this ground truth table, it can be assumed that a VPN is used. Put differently: If the latency measurement from a certain connection doesn't correlate with the ground truth table, there could be a VPN.
This detection test has several weaknesses:
- IP to location databases are not always accurate
- Measuring and comparing different latency samples suffers from many problems as outlined here.
- It is unclear what "certain region" means. How should the target region be defined? In practice, the detection test should use the N nearest ground truth table regions that are available.
- A major problem with this approach is that latencies taken from different points in time are compared. The Internet is never the same at two different points of time and this affects also latency measurements.
Latency Triangulation
The idea behind latency triangulation leverages the fact that a server can be strategically placed such that the geographical and hop distance to the end user is minimized. This key fact is used with CDN and Internet Acceleration providers such as Cloudflare or Fastly. By reducing the geographical and hop distance, the latency is usually linearly decreased as well.
As stated before, VPN's can be considered as artificial Internet hop placed between client and server. A client A first sends the packet to the VPN server V and then the VPN server sends the packet to the destination server D. Therefore, there are two distances:
- Distance Client to VPN (C <--> V)
- Distance VPN to Destination (V <--> D)
If the latency is minimized by finding a server as close as possible to the client, the following two cases can be distinguished:
- Client uses a VPN: The destination D considers the VPN V to be the client. It doesn't matter how close the destination server is to the client, there will always remain the distance Client to VPN (C <--> V) in the connection. Therefore, latency optimization will converge to the amount Client to VPN (C <--> V). If this distance is significant, it is a clear indication that a intermediate hop is in the connection.
- Client not using a VPN: The latency to the client can be reduced to a small latency such as 1ms to 30ms.
In theory, it is hard to find the cutoff to what constitutes a latency that is so small that there is no potential VPN between client and server. In practice, many VPN providers are hosting their VPN servers in commercial datacenters. Those datacenters are closely placed to large Internet Exchange Points (IXPs). Since the latency minimizing technique also uses servers hosted in datacenters, the latency can be often reduced to very small numbers.
Datacenter Check
As with proxies, a lot of VPN's are actually hosted in cloud / datacenter computing instances. Therefore, it is always good to know whether an IP address belongs to cloud IP address ranges such as Amazon AWS or Microsoft Azure.
Put differently, the set of IP addresses belonging to an VPN provider and the set of IP addresses belonging to a hosting provider are often overlapping. Therefore, it is a good idea to check whether the IP address belongs to a hosting provider by using IP to Hosting Databases.
Potential Detection Methods
DPI Anomalies
The idea with this approach is to generate a tcpdump traffic capture generated from visiting a
very simple HTML site with various modern browsers (Chrome, Safari, Firefox).
- Using a VPN: The HTML site is visited with a VPN and the traffic capture is stored as
vpn_traffic.pcap - Not using a VPN: The simple HTML site is visited without a VPN and the traffic capture
is stored as
non_vpn_traffic.pcap
It is very important that the two different traffic captures are generated with the same client, the same browser and that the same web server is used.
After having generated the two .pcap files, the next task is to compare both .pcap
files by comparing each single packet. All header fields should be compared (IP header, TCP header, UDP
header) and the payload should be compared as well.
For each difference found between the two traffic captures, it must be decided whether this difference can be explained as caused by the VPN. This process is a very time consuming process. The process looks like this:
- Differences found in the IP Header:
IP.src: The source IP address is different. However, just because the source IP address is different, it does not mean that a VPN is used.IP.sum: The IP checksum is different. However, the checksum must be different, since other IP header fields are variable for reasons other than VPN usage.- And the rest of the IP header fields...
- Differences found in the TCP Header:
TCP.sport: The source port is different. Source ports are randomized and this does not explain VPN usage.- And the rest of the TCP header fields...
- Differences found in TCP payloads:
Theory Deep Dive
Latency, RTT and the Internet
Latency and RTT are used for VPN and proxy detection on this website. RTT is defined as:
RTT = Latency * 2. Many of
the detection tests on this site use latency and especially latency triangulation in order to detect proxies
and VPN services. Is this scientifically even possible? Several questions need to be answered:
- How can latency be measured?
- What factors constitute latency? Is latency only constrained by the speed of light?
- Does latency correlate with geographical distance? Can latency be used to triangulate hosts geographically?
- Can ICMP (ping) latency be compared to UDP/TCP latency?
The main purpose of this theoretical deep dive is to derive practical rules for working with latency in regards to VPN and proxy detection. To put it in a blunt way: Latency carries too much valuable information for proxy and VPN detection to be ignored, but is notoriously difficult and sometimes impossible to work with.
How can latency be measured?
Latency can be measured on different layers of the network stack and also with different protocols:
- Ping/ICMP
- TCP or UDP
- From the browser with JavaScript:
Measuring latency with the famous ping tool is probably the best known method:
$ ping -c7 172.217.18.14
PING 172.217.18.14 (172.217.18.14): 56 data bytes
64 bytes from 172.217.18.14: icmp_seq=0 ttl=119 time=24.908 ms
64 bytes from 172.217.18.14: icmp_seq=1 ttl=119 time=24.405 ms
64 bytes from 172.217.18.14: icmp_seq=2 ttl=119 time=26.583 ms
64 bytes from 172.217.18.14: icmp_seq=3 ttl=119 time=29.612 ms
64 bytes from 172.217.18.14: icmp_seq=4 ttl=119 time=25.298 ms
64 bytes from 172.217.18.14: icmp_seq=5 ttl=119 time=30.149 ms
64 bytes from 172.217.18.14: icmp_seq=6 ttl=119 time=28.938 ms
--- 172.217.18.14 ping statistics ---
7 packets transmitted, 7 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 24.405/27.128/30.149/2.222 msHowever, if a server accepts incoming UDP or TCP flows, you can also measure latency with UDP or TCP. The nmap tool nping can be used to conduct latency measurements on a variety of different protocols. For example in order to measure latency with TCP on port 80, the following command can be used:
$ sudo nping -p 80 -c7 -q --tcp 172.217.18.14
Starting Nping 0.7.93 ( https://nmap.org/nping ) at 2023-02-17 18:23 CET
Max rtt: 57.250ms | Min rtt: 54.324ms | Avg rtt: 55.722ms
Raw packets sent: 7 (280B) | Rcvd: 7 (322B) | Lost: 0 (0.00%)
Nping done: 1 IP address pinged in 6.08 secondsFrom the two examples above, it can be seen that the ping latency was faster than the TCP latency. Of course, just by making two simple measurements, this generalization cannot be drawn. However, the test above already demonstrates one factor that influences latency measurements: Which protocol was used (ICMP vs TCP).
What constitutes latency?
Latency can be broken down into three components: [1]
- Time taken for the packets to traverse down the stack (from the application, via sockets API, network, link)
- Time taken for the frames to reach the recipient (includes transmission delay, propagation delay, and queueing delay, but also number of hops and peering agreements)
- Time taken for the packets to traverse up the stack on the recipient
There are a lot of factors that influence the time taken for a packet to travel between two hosts in the Internet. For example, the physical distance between the hosts plays an important role. The speed of light in vacuum is 300 km/msec, and about 180 km/msec in fiber optic cable. And about 150 km/msec for electrons in copper wire [Source]. Therefore, the latency needs to be at least as large as the transmission speed in fiber cables allows to travel.
However, the latency is also affected by the number of hops (routers, switches and servers) that the packet is passing through. Each hop that a packet has to pass through causes processing, caching or queueing delays. Those delays are substantial. The amount of processing routers are doing also depends on the payload of the packet and the packet type. For example, packets to non-standard ports might be affected by more detailed Deep Packet Inspection filters than packets to standard ports. This also holds for the protocol type. ICMP traffic is often depressed:
Even more dangerously, I'll hear "the link / server / network / internet is slow - look at my ping times!". Using Ping as a measure of RTT (Round Trip Time) performance is no longer a good way to go. Many ISPs now depress the priority of ICMP packets, so that they'll transport it, but they'll give priority to "real" traffic like HTTP, HTTPS or SMTP. [Source]
Furthermore, the latency is also heavily affected by politics and routing agreements between ISPs. Even though two ISPs are very close in terms of geographical distance, bad routing policies might increase the latency artificially.
Another factors that impacts latency measurement is the dynamic routing of IP packets. There is no guarantee that two packets take the same routing path to the destination. And that there is even less of a guarantee that two latency measurements taken with multiple samples have all taken the same path. Peering agreements and routing tables can change at any point in time.
The idea behind latency measurements assumes that the target has seen the probing packet. But is this necessarily the case? With ICMP, there is no guarantee that not some router close to the destination answers the ICMP echo request instead of the real destination. This likely does not happen often in reality (And probably not at all with TCP or UDP traffic), but it cannot be excluded. Put differently: How can it be ensured that the latency was in fact measured to the destination?
An additional complexity is the fact that the two latencies that constitute the RTT are not necessarily
symmetric. Put differently: When a packet travels from host A to host B, the routing path A -> B is not
necessarily the same as the route back B -> A. Therefore, the equation RTT = Latency * 2
introduced above does not necessarily have to be true.
Last but not least, latency is also heavily impacted by the computational load of the systems that take the latency measurements. If a server is under heavy load, the latency can be increased significantly. The same applies to clients.
It can be concluded that latency of packets sent in the Internet are not only influenced by geographical distance, but by many other factors.
Does latency correlate with geographical distance? Can it be used for Triangulation?
In the section above it was mostly shown how other factors than geographical distance affect latencies in the Internet. While it is certainly true, geographical distance is still the main factor that constitutes latencies.
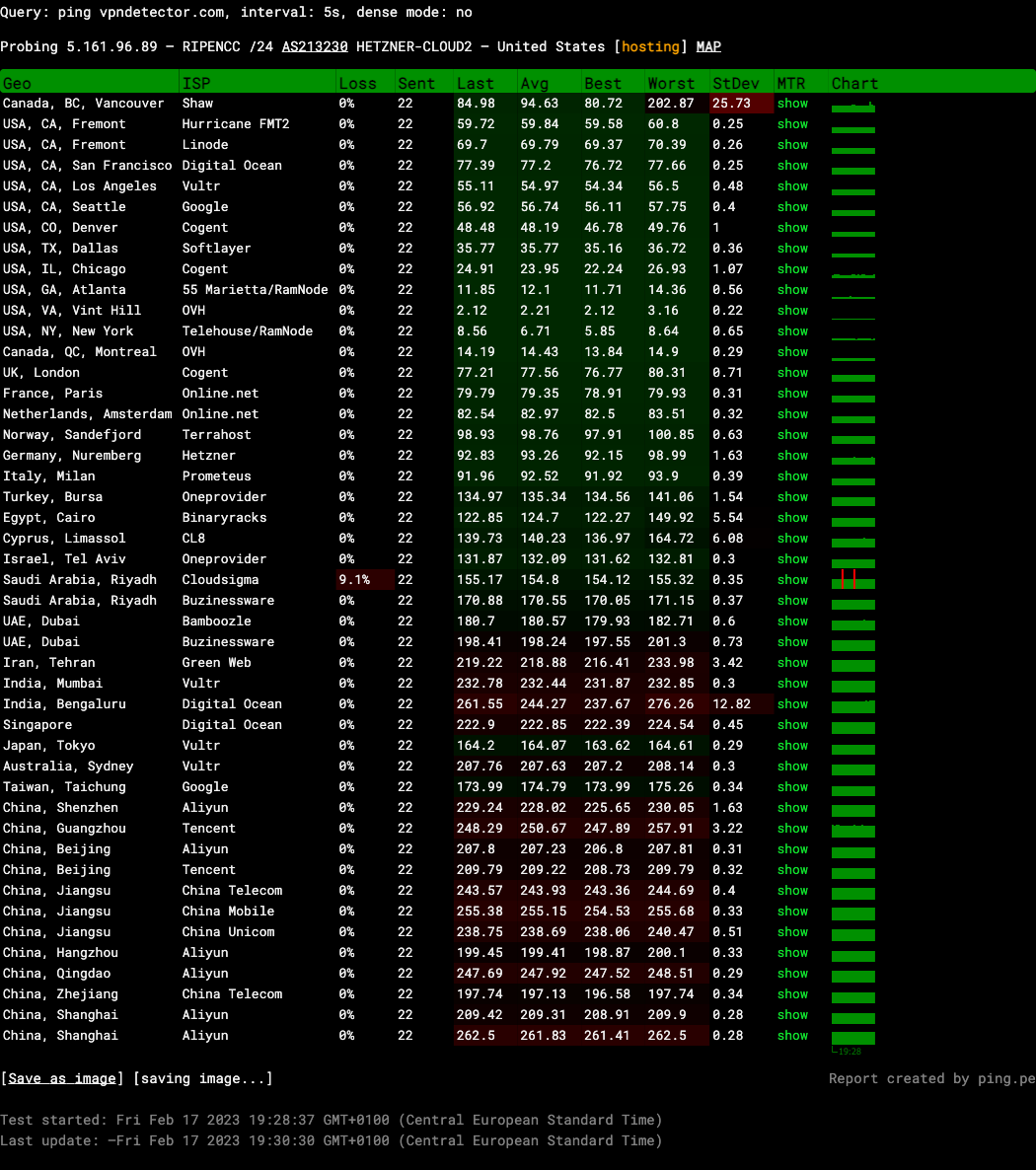
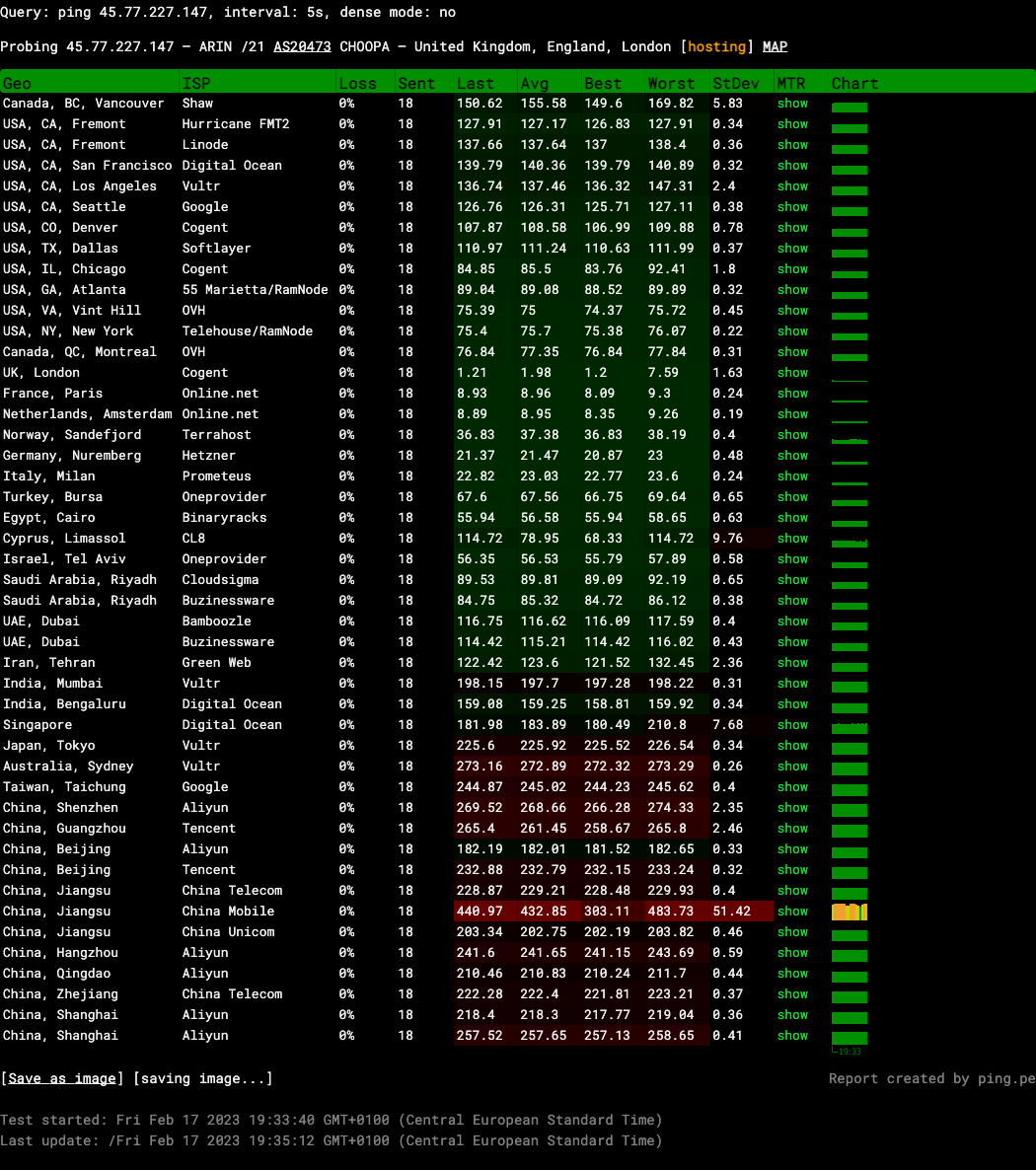
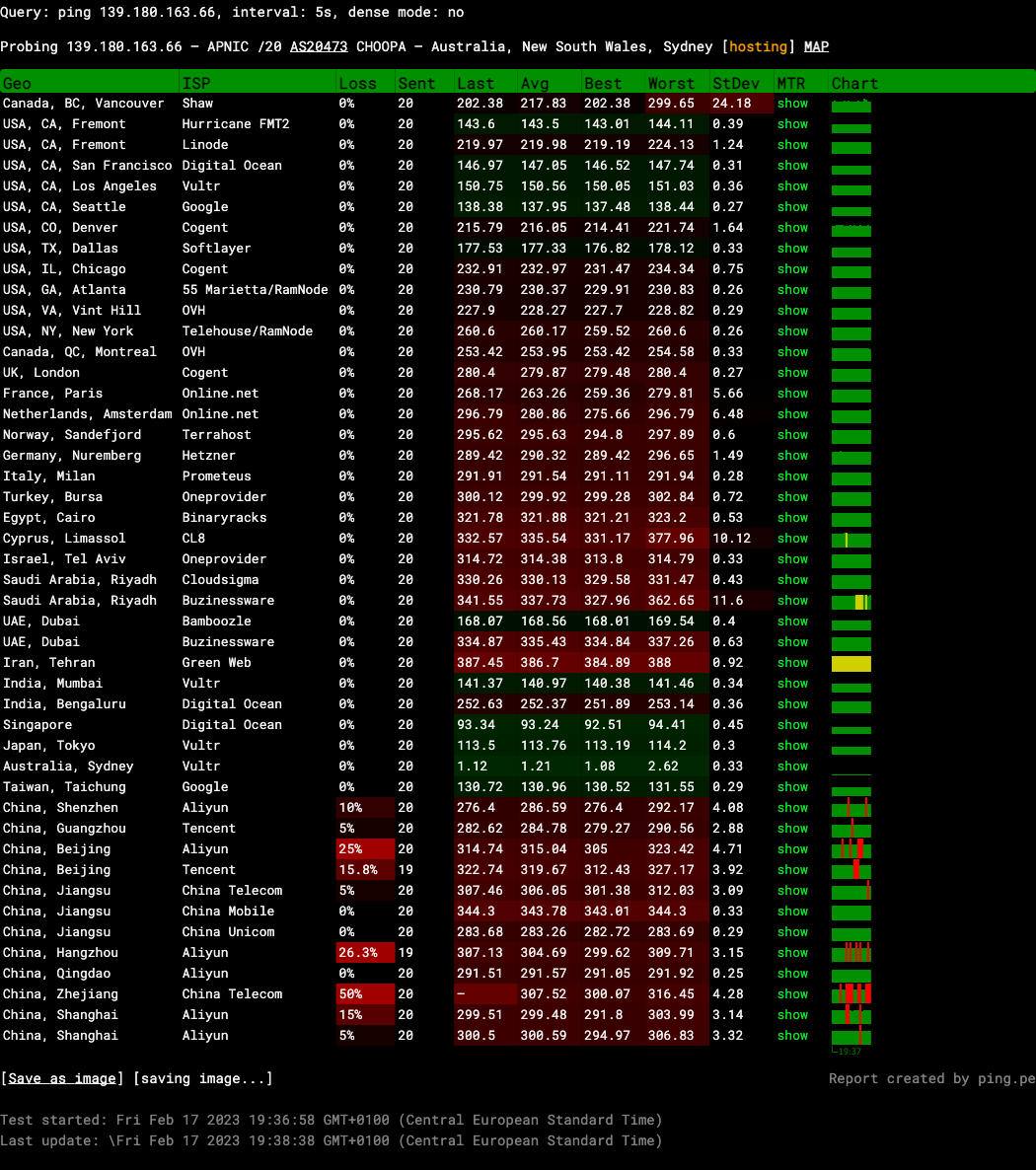
As a quick experiment, the tool ping.pe is used to collect the latencies from more than twenty different servers to three different testing servers (From which the locations are known):
Ping to server in Ashburn, Virginia, USA
Ping to server in London, UK
Ping to server in Sydney, Australia
Conclusion
A lot can be learned from the above three ping measurements conducted with ping.pe: In all three cases, the ping server located in the same region or city as the destination server has by far the smallest average ping latency.
For example, in Figure 1, the ping server located in Vint Hill, VA, USA has an average latency of 2.21ms to the destination in Ashburn, Virginia, USA. The latency is small because the two locations are only 50km apart. When looking at other locations close to the target location (such as Atlanta or New York), the latencies are also small (11.85ms and 8.56ms). We see a clear correlation between geographical distance and ping latency.
On the other side, just because two hosts have the same geographical distance to each other, does not necessarily mean that they have the same latencies: In Figure 1, the best latency from Taiwan, Taichung measures 173.99ms and the best latency from China, Guangzhou measures 247.98ms. Both cities have more or less the same distance to the server in Ashburn, Virginia, USA, but the latencies differ significantly.
In all three examples above, ping latencies between data center hosts are measured. Both client and server are located in datacenters. Datacenter infrastructure is often very closely placed at Internet Exchange Points (IXP). This does not apply to normal Internet users.
Having said all of the above, there is a law regarding latencies: If the geographical location of the server is known and the latency was obtained, the distance of the client cannot be farther away as the maximum speed of the transmission medium allows. Put differently: The client cannot be farther away as the speed of light can travel in the measured latency time.
With this observation, the question "Can Latency be used for Triangulation?" can be answered with a Yes.
By the law of the speed of light not being able to exceed 180 km/msec in fiber optic cable, the real location in the above three examples cannot be farther away than:
- Figure 1:
2.21ms / 2 * 180km/ms = 198.9kmfrom USA, VA, Vint Hill (Real distance is ~50km) - Figure 2:
1.2ms / 2 * 180km/ms = 108kmfrom London UK (Real distance less than ~20km) - Figure 3:
1.08ms / 2 * 180km/ms = 97.2kmfrom Sydney, Australia (Real distance less than ~20km)
In practice, ping (ICMP) cannot be used to measure the latency to arbitrary Internet users. Therefore, other latency measurement tools such as TCP or WebSockets have to be considered. Those protocols can be slower than ping (ICMP).
Can ICMP (ping) latency be compared to UDP/TCP latency?
It is very dangerous to compare latencies obtained with ICMP to latencies obtained by other means (Such as TCP or UDP). ICMP is treated different compared normal TCP and UDP traffic. There are differences in the protocol layer and differences on the packet routing layer. Many ISP's deprioritize ICMP traffic nowadays, since ICMP is not a protocol that carries application data. Furthermore, it cannot be assumed that ICMP takes the same routing path as ordinary TCP or UDP traffic.
Furthermore, there is an additional delay in processing TCP segments. TCP is treated entirely different during Internet routing compared to raw IP packets. In the network stack, TCP's latency is increased by packet-reassembly, congestion control and by ensuring the order of packets.
In some circumstances, latencies obtained by two different protocols can be compared.
Practical Rules for working with Latencies
In conclusion to the theory introduced above, in regards to proxy and VPN detection, there are some practical rules to work with latencies and RTT.
Rule 1 - The speed of light sets a strong upper bound for the maximum distance
Explanation: The smallest latency measurement from N samples multiplied with the speed of light determines the maximum distance two hosts can be apart.
Example: If a client makes 10 latency measurements to a server and obtains 1.7ms as the smallest RTT sample, the maximum distance can be obtained as follows: The latency is RTT/2 = 0.7ms. The speed of light is 180 km/msec in fiber optic cable. The maximum distance can be: 0.7ms * 180km = 126km.
Rule 2 - Only latencies taken with the same protocol should be compared
This rule is simple: Latencies taken with different tools (ping or nping) and different protocols (ICMP or TCP) should not be compared in order to derive conclusions. The reason is simple: Different protocols may take different routing paths and may be either prioritized or penalized. For example, ICMP traffic nowadays is often penalized and slowed down compared to TCP and UDP.
Rule 3 - Only the smallest latency sample should be considered
As explained above in-depth, there are many reasons why a packet in the Internet travels longer than the speed of light allows in theory. Only the smallest latency value from any given sample of latency measurements should be selected for comparison.
Why should only the smallest latency value be taken into account? As long as the measurement really measured the round trip time between client and server (And not some man in the middle replied instead of the server), the speed of light sets an upper bound for the maximum distance between client and server.
References
- Why ping is not a reliable way to measure latencies: Ping is Bad (Sometimes) [2011]
- The following article investigates the possibility to geo-locate VPN servers by using ping. They conclude: "If you have data from enough probes, and find a minimum rtt under ~3 msec, you can often pin down server location within 100 km or less.": How to verify physical locations of Internet servers [2020?]
Tools
- This tool allows to test TCP latencies to different servers on the globe. The latency test is conducted by repeatedly loading small images with JavaScript. TCP Latency Test
- meter.net manages over 100 servers located across the planet. The test measures the WebSocket latencies from the browser to each of the 100 servers: World Ping Test using WebSockets
- ping.pe is an excellent tool that allows to ping (ICMP) an IP address or domain from over 20 locations around the globe at the same time: World Ping (ICMP) Test